
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 데이콘
- 여수광양항
- 항해학부
- 해양수산부
- 청년빅데이터캠퍼스
- 빅데이터경진대회
- 충청남도 청년네트워크 위원회
- 해사법
- 빅데이터
- YGPA 공공데이터 활용 비즈니스 공모전
- 머신러닝
- HSK
- 현대중공업빅데이터경진대회
- 해양빅데이터
- 항해사
- fastai
- 한국해양대학교
- 해양수산빅데이터활용공모전
- 펭귄몸무게예측대회
- 해양수산빅데이터경진대회
- 여수광양빅데이터경진대회
- 딥러닝
- AI
- 유니스트
- 해양수산빅데이터
- 인생
- 해상교통법
- 선원법
- 선박직원법
- 조선빅데이터
- Today
- Total
경 탁
[Fast ai와 파이토치가 만나 꽃피운 딥러닝] #3 본문

금 포스팅에서는 MNIST 데이터를 통해 간단한 모델링을 하고 손실함수를 통해 파라미터를 조정하는 내용을 다룰 예정입니다.
본격적인 코드에 들어가기 앞서, 파라미터를 조정하는 '경사하강법'에 대해 짚고 넘어갈까 합니다.
0. 경사하강법
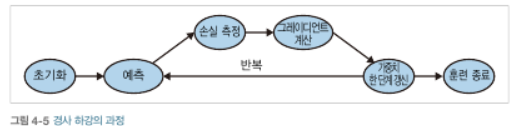
파라미터란 변수를 의미합니다. 예를 들어 중학교때 배운 기초적인 함수 1차 함수에서
Y = ax + b // 여기서 a와 b를 파라미터라고 칭합니다.
보다 정확도가 높은 함수를 만들기 위하여 파라미터를 조정합니다. 본 포스팅에서는 임의로 '초기화'할 예정입니다.
그리고 그 값으로 예측하고 정답과 예측값의 차이를 측정합니다.
여기서 쓰이는 것이 '손실함수' 입니다. (저번 포스팅에서 다룬 L1 / L2 역시 손실함수의 일종입니다.)
그리고 그 그레디언트를 계산하고 이를 통해 가중치를 한단계 갱신합니다.
이러한 루틴으로 흘러간다고 생각하시면 될 듯합니다.
즉 쉽게 생각해 가장 값을 잘 맞추는 함수의 '파라미터'를 구하면 된다 ! 입니다 ㅎㅎ
더 깊게 들어가면 초기 파라미터의 값을 어떻게 맞추는 지 ... 혹은 가중치를 갱신할 때 사용되는 '학습률' 등등 다뤄야할 내용이 많지만, 본 포스팅에서는 가볍게 넘어가겠습니다 :-) (사실 저도 잘 몰라용 ㅎㅎ)
1. 데이터 준비 및 지난 과정 정리
from fastai import *
from fastbook import *
path = untar_data(URLs.MNIST_SAMPLE)
threes = (path/'train'/'3').ls().sorted()
sevens = (path/'train'/'7').ls().sorted()
seven_tensors = [tensor(Image.open(s)) for s in sevens]
three_tensors = [tensor(Image.open(o)) for o in threes]
stacked_sevens = torch.stack(seven_tensors).float()/255
stacked_threes = torch.stack(three_tensors).float()/255
valid_3_tens = torch.stack([tensor(Image.open(o)) for o in (path/'valid'/'3').ls()])
valid_3_tens = valid_3_tens.float()/255
valid_7_tens = torch.stack([tensor(Image.open(o)) for o in (path/'valid'/'7').ls()])
valid_7_tens = valid_7_tens.float()/255 지난 과정까지 따라오셨다면 위 코드들이 무엇을 의미하시는 지 아실거라 생각합니다 !
가볍게 패스하도록 하죠 !
참고로 valid 가 붙은 것들은 '검증용 데이터셋'입니다. 쉽게 비유를 하겠습니다.
고3 경탁이가 수능을 친다고 가정합시다. 수능을 준비하기 위해 수능특강을 풉니다.
그리고 9월 모의고사때 시험을 치겠죠 ? 최종적으로 11월에는 수능을 칠겁니다.
여기서 (수능특강=Train dataset // 모의고사=Valid dataset // 수능 =Test dataset) 입니다.
train_x = torch.cat([stacked_threes, stacked_sevens]).view(-1, 28*28)
train_y = tensor([1]*len(threes) + [0]*len(sevens)).unsqueeze(1)
train_x.shape, train_y.shape
dset = list(zip(train_x, train_y))
x,y = dset[0] Train data의 3 이미지와 7 이미지를 한 곳에 묶어 Train X 라는 데이터로 묶어줍시다.
사실 순서대로 묶이기 때문에 3 이미지 뒤에 7 이미지가 쌓이는 식으로 묶일 것입니다.
그리고 Y 데이터를 생성해줍니다.
뒤에 unsqueeze(1)은 1차원으로 배열하라는 의미입니다.
Shape를 보게되면

이렇게 연습용 X 데이터와 Y 데이터의 개수가 맞음을 알 수 있습니다 (중요)
그리고 X 데이터와 Y 데이터를 List로 묶어주게습니다.
valid_x = torch.cat([valid_3_tens, valid_7_tens]).view(-1, 28*28)
valid_y = tensor([1]*len(valid_3_tens) + [0]*len(valid_7_tens)).unsqueeze(1)
valid_dset = list(zip(valid_x, valid_y)) Valid dataset도 마찬가지 작업을 시행해줍니다.
2. 가중치 초기화
def init_params(size, std=1.0): return (torch.randn(size)*std).requires_grad_()
weights = init_params((28*28,1))
bias = init_params(1) 가중치를 무작위로 초기화해주는 함수를 생성해주십니다.
그리고 가중치(W) 및 편향(b)을 생성해줍시다.
'무작위'이며 편향은 1차원 텐서로 만들어주도록 합시다.
0차원으로 만들경우 하나의 값에만 편향이 들어가기 때문입니다.
과정을 쉽게 파악해보도록 하겠습니다.

train_x 데이터의 첫번째 이미지의 픽셀값에

무작위로 생성된 가중치를 곱해주고 (.T는 행렬을 바꿔주기 위해서입니다.)

이를 다 더해줍니다.

그런뒤 편향을 더해줍니다.
이로써 기초적인 데이터 정립 및 가중치 초기화는 완료되었습니다.
다음 포스팅에서는 기초적인 모델링 및 그 이후의 과정을 다루도록 하겠습니다 :-)
'- 공부 > 2. AI' 카테고리의 다른 글
| [Fast ai와 파이토치가 만나 꽃피운 딥러닝] #4 (0) | 2022.01.15 |
|---|---|
| [Fast ai와 파이토치가 만나 꽃피운 딥러닝] #2 (0) | 2022.01.10 |
| [Fast ai와 파이토치가 만나 꽃피운 딥러닝] #1 (0) | 2022.01.02 |
| [데이콘] 펭귄 몸무게 예측 경진대회 #3 (0) | 2021.12.31 |
| [데이콘] 펭귄 몸무게 예측 경진대회 #2 (0) | 2021.12.29 |


