
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- YGPA 공공데이터 활용 비즈니스 공모전
- 머신러닝
- 한국해양대학교
- 항해사
- 인생
- 선원법
- 항해학부
- 해양수산빅데이터경진대회
- 여수광양빅데이터경진대회
- fastai
- 조선빅데이터
- 해양수산빅데이터
- AI
- 충청남도 청년네트워크 위원회
- 청년빅데이터캠퍼스
- 빅데이터
- 해상교통법
- 해양수산빅데이터활용공모전
- 해사법
- 여수광양항
- 빅데이터경진대회
- 펭귄몸무게예측대회
- 데이콘
- HSK
- 현대중공업빅데이터경진대회
- 딥러닝
- 선박직원법
- 해양수산부
- 유니스트
- 해양빅데이터
- Today
- Total
경 탁
[Fast ai와 파이토치가 만나 꽃피운 딥러닝] #4 본문

본 포스팅에서는 개/고양이 이미지를 통해 두 동물을 분류하는 모델링을 해보도록 하겠습니다.
1. 데이터 준비
from fastai.vision.all import *
path = untar_data(URLs.PETS)데이터를 다운받게 되면 지정한 곳에 데이터가 저장되게 됩니다.
2. DATABLOCK
pets = DataBlock(blocks = (ImageBlock, CategoryBlock),
get_items=get_image_files,
splitter=RandomSplitter(seed=42),
get_y=using_attr(RegexLabeller(r'(.+)_\d+.jpg$'),'name'),
item_tfms=Resize(460),
batch_tfms=aug_transforms(size=224, min_scale=0.75))
dls = pets.dataloaders(path/'images') FASTAI에는 DATABLOCK 이라는 API가 있습니다.
자세한 내용은 'https://docs.fast.ai/tutorial.datablock.html' 을 참조해주시면 될것 같습니다.
DATABLOCK은 데이터의 청사진입니다. 즉 데이터를 조립하는 상세한 계획이라고 할 수 있습니다.
그리고 이를 DATASET으로 전환할지 DATALOADERS 로 전환할지 선택할 수 있습니다.
(본 코드에서는 DATALOADERS로 전환했습니다.)
그 외에도 데이터를 어떤 방식으로 가져오느냐 (이미지 파일로 변환하여 불러옵니다.)
SPLITTER 를 지정하여 무작위였던 SEED를 일정값으로 맞춰주기,
라벨값을 어떻게 지정하느냐가 있습니다. (정규표현식 참조)
하위 내용에서는 DATASET&DATALOADER의 차이를 다루고 이미지 변환에 대해 다루겠습니다.
2.1 DATASET & DATALOADERS
DATASET은 데이터셋의 특징을 가져오고 라벨을 지정하는 일을 합니다.
즉 위의 예시로 들면, 고양이 이미지 & 강아지 이미지를 갖고 와서 이미지에 고양이인지 강아지인지 지정하는 역할을 하하는 것입니다.
하지만 모델링을 진행할때는 그것만으로는 부족합니다.
샘플들을 미니배치로 나누고 매 에폭마다 데이터를 다시 섞어서 과적합을 막아야하기 때문입니다.
이 역할을 해주는 것이 DATALOADER 입니다.
2.2 크기 조절
item_tfms=Resize(460),
batch_tfms=aug_transforms(size=224, min_scale=0.75)) 텐서로 포장된 이미지를 GPU로 전달하기 위해서는 이미지가 모두 같은 사이즈여야합니다.
그리고 가능한 적은 변형 작업으로 데이터 증강을 수행하고 이미지를 같은 크기로 변형하는 것이 좋습니다.
일반적으로 이 문제를 해결하기 위해서 이미지의 크기를 상대적으로 크게 만들고 이미지에 공통적으로 적용할 증강 연산을 하나로 구성하여 처리 마지막 단계에서 조합된 연산들을 GPU가 한번만 수행하게 됩니다.
개별 이미지에 증강연산과 보간법을 수행하는 것과는 대조되는 방식입니다.
위에서 설명한 첫번째 단계인 크기 조절에서 이미지를 충분히 키웁니다. 즉 빈 영역을 만들지 않기 위해서입니다.
그리고 이미지의 일부를 잘라내어 크기를 조절합니다. 그때 조절하는 방식이 2가지 입니다.
- item_tfms : 전체 너비나 높이를 기준으로 잘라내는 단계 / GPU로 복사되기 전 개별 이미지에 적용하는 부분
- batch_tfms : 임의의 부분을 잘라낸 후 증강하는 단계 /
3. 모델링
learn = cnn_learner(dls, resnet34, metrics=error_rate)
learn.fine_tune(2) 모델링은 RESNET34를 이용하여 했습니다.
평가지표는 에러율(error_rate) 입니다.
3.1 RESNET
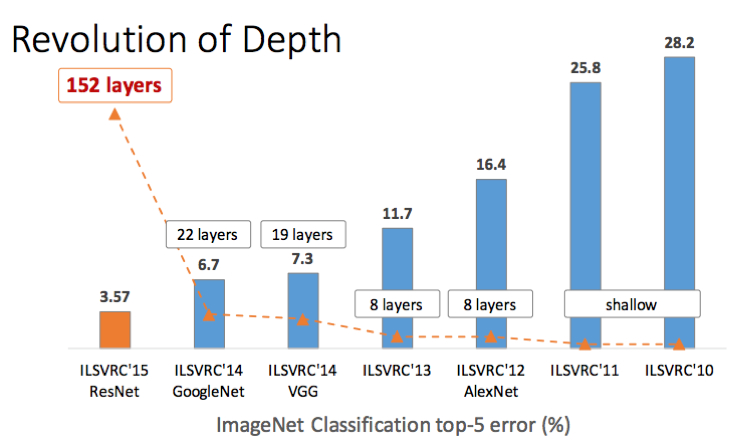
RESNET은 2015년 ILSVRC에서 우승을 차지한 모델, 마이크로소프트의 북경연구소에서 개발한 알고리즘이다.
(벌써 7년이 지난 알고리즘이다..시간아..천천히 가다오...!)
RSENET의 핵심은 Residual Block이다.
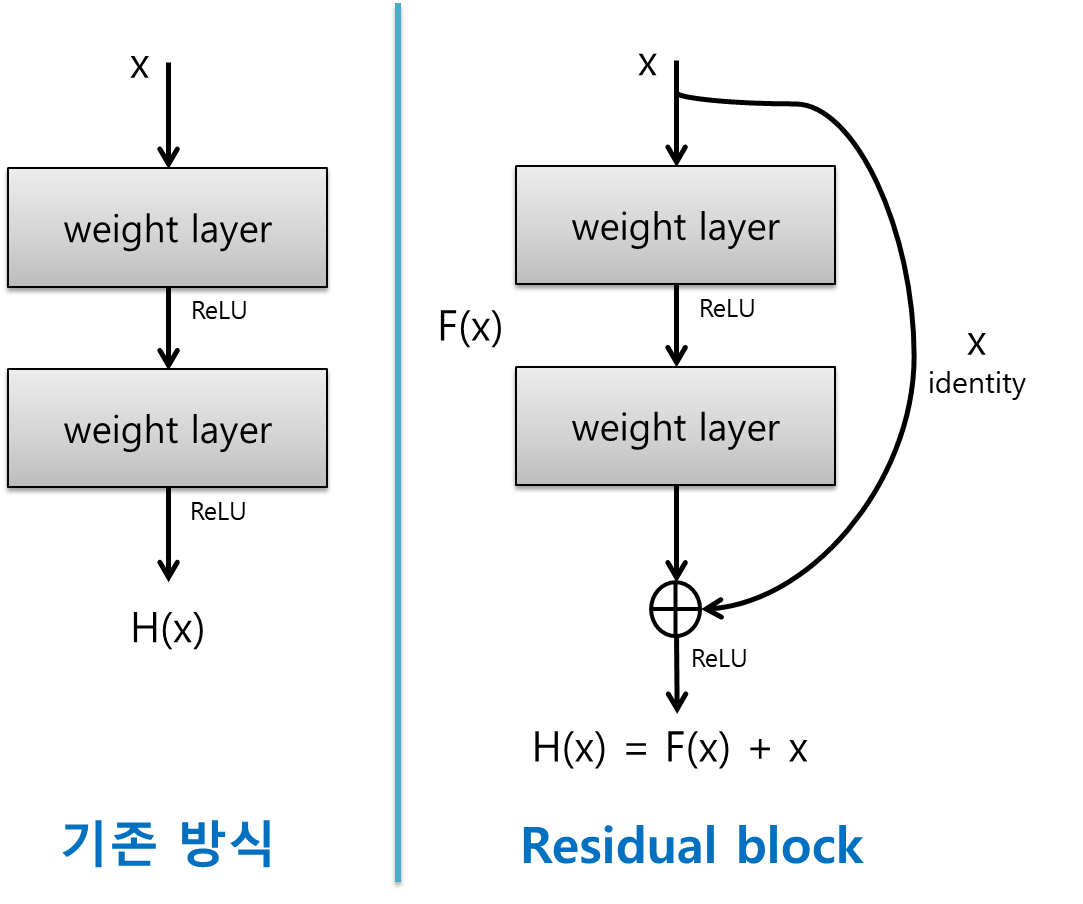
RESNET은 H(x)을 최소화하는 것을 목적으로 한다. 입력값 X는 변하지 않으므로 F(x)을 0에 가깝게 하는 것이다.
즉 H(x)-x (잔차-residual)을 최소로 해주는 것이므로, RESNET이란 이름이 붙게 된다.
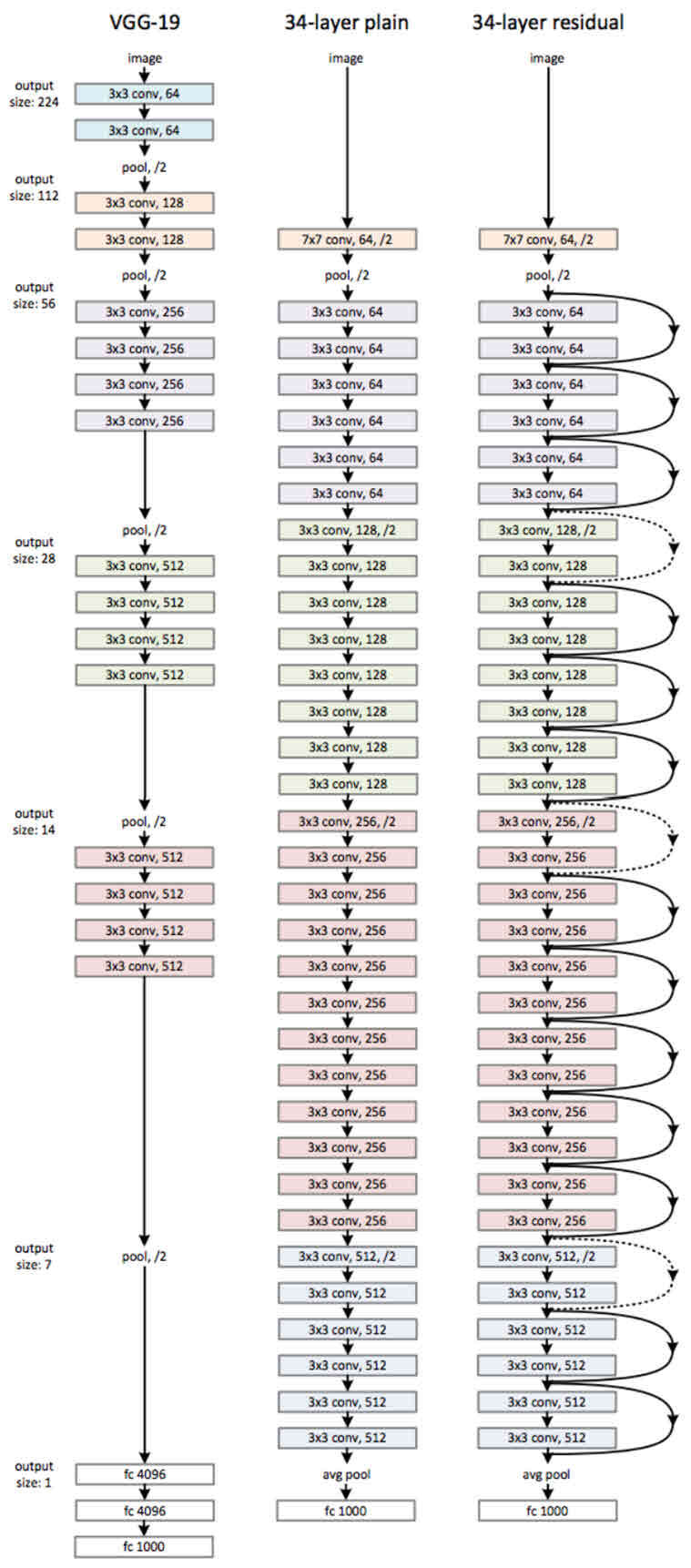
균일하게 3X3 사이즈의 컨볼루션 필터를 사용하고 X identity를 끊임없이 이어준 것을 알 수 있다.
'- 공부 > 2. AI' 카테고리의 다른 글
| [Fast ai와 파이토치가 만나 꽃피운 딥러닝] #3 (0) | 2022.01.11 |
|---|---|
| [Fast ai와 파이토치가 만나 꽃피운 딥러닝] #2 (0) | 2022.01.10 |
| [Fast ai와 파이토치가 만나 꽃피운 딥러닝] #1 (0) | 2022.01.02 |
| [데이콘] 펭귄 몸무게 예측 경진대회 #3 (0) | 2021.12.31 |
| [데이콘] 펭귄 몸무게 예측 경진대회 #2 (0) | 2021.12.29 |


